Você não tem problema de prompt — tem problema de contexto ou de harness

Você já ficou meia hora refinando um prompt, tentando deixar as instruções mais claras, mais detalhadas, com exemplos, com restrições — e o agente continuou errando da mesma forma?
Já passou por isso: o modelo alucina mesmo com o prompt perfeito. Ou pior: o agente age no mundo, faz uma coisa que não deveria, e você vai descobrir isso em produção. Não no chat de testes, não no sandbox. Em produção, com dado real.
Isso não é problema de prompt. E polir o texto do sistema prompt não vai resolver.
Esse artigo é sobre entender onde o problema de fato está — e por que confundir as três camadas de engenharia de IA custa tempo, dinheiro e, às vezes, incidentes.
As três disciplinas que viraram sinônimos (e não deveriam ser)
O mercado jogou tudo no mesmo saco: "prompt engineering". Você quer que o modelo responda melhor? Escreve um prompt melhor. Quer um agente mais confiável? Prompt melhor. Quer reduzir alucinação? Prompt melhor.
Funciona num nível básico. Mas quanto você começa a construir coisa real — um agente que lê arquivo, abre PR, manda email, consulta banco — essa visão começa a rachar. E as rachaduras aparecem justamente onde mais dói: em produção.
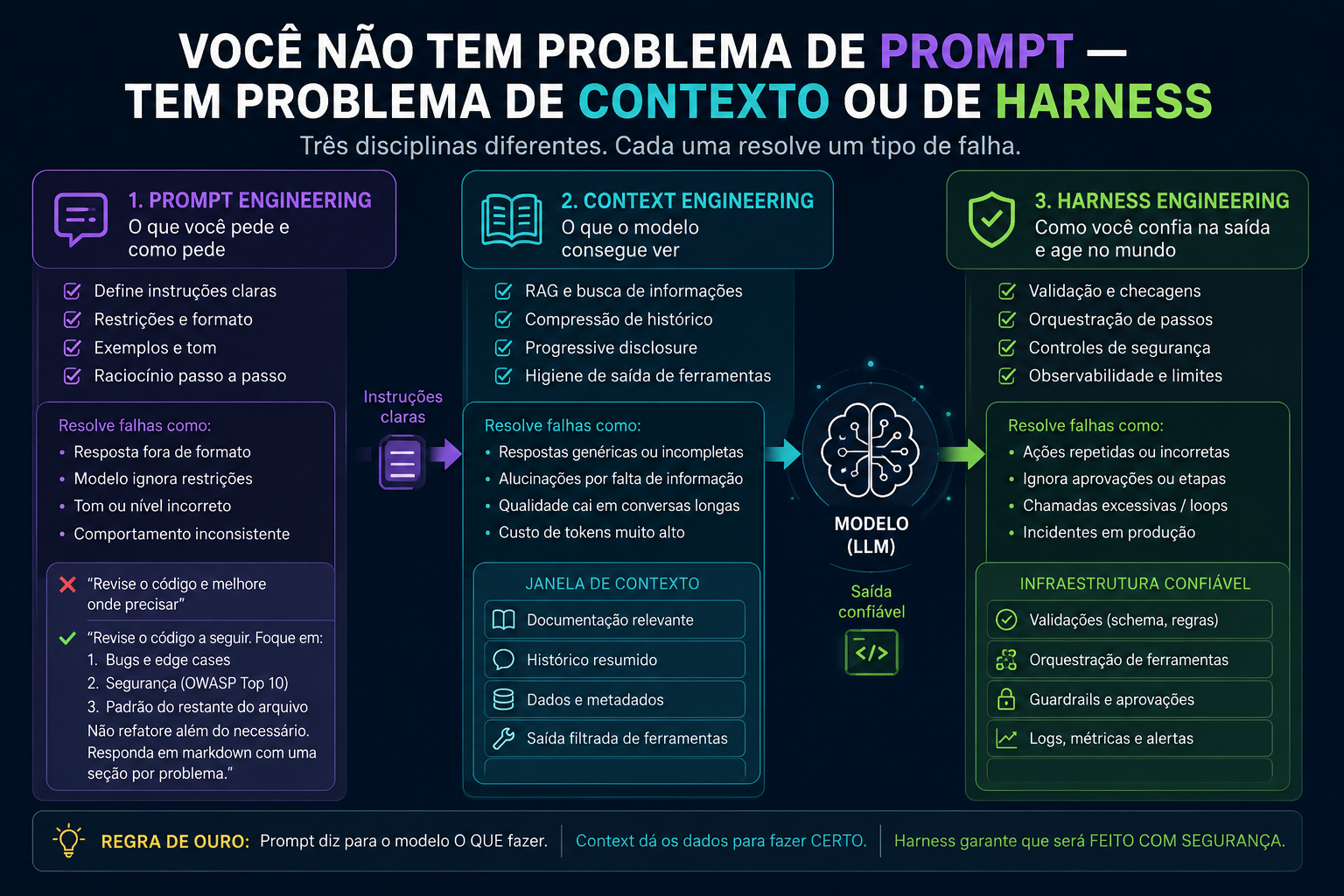
Andrej Karpathy foi um dos primeiros a colocar nome nisso de forma clara: o que a maioria chama de prompt engineering é na verdade Context Engineering — "a arte delicada e a ciência de preencher a janela de contexto com exatamente as informações certas". E existe ainda uma terceira camada que quase ninguém fala, que é o Harness — a infraestrutura que envolve o modelo e converte saída probabilística em software confiável.
São três disciplinas separadas. Cada uma resolve um conjunto diferente de falhas. Confundi-las leva a esforço no lugar errado.
Prompt Engineering: o que você pede e como pede
Prompt Engineering é a camada mais visível. É onde você define:
- O papel do modelo ("você é um revisor de código sênior...")
- As restrições ("nunca delete arquivos sem confirmar")
- O formato da resposta (JSON, markdown, lista numerada)
- Os exemplos de comportamento esperado (few-shot)
- O raciocínio passo a passo (chain-of-thought)
É uma disciplina real, tem técnica, tem resultado. Quando o modelo produz saída inconsistente, fora de formato, com tom errado, ou faz coisas que você explicitamente disse pra não fazer — você tem um problema de prompt.
O erro mais comum aqui é ser vago. O modelo não vai "entender o que você quis dizer". Ele vai seguir o que você escreveu.
❌ "Revise o código e melhore onde precisar"
✅ "Revise o código a seguir. Foque em:
1. Bugs e edge cases não tratados
2. Violações de segurança (OWASP Top 10)
3. Inconsistências com o padrão do restante do arquivo
Não refatore além do necessário. Responda em markdown com uma seção por problema encontrado."
Quando investir em prompt:
- A resposta vem no formato errado
- O modelo ignora restrições que você definiu
- O tom ou nível de detalhe está incorreto
- O comportamento é inconsistente entre chamadas similares
Quando parar de mexer no prompt: Quando o modelo responde certo para o que você perguntou, mas a informação que ele tem é errada ou incompleta. Aí o problema não é o prompt.
Context Engineering: o que o modelo consegue ver
Aqui é onde o jogo muda. E onde a maioria das falhas reais de agentes em produção mora.
Context Engineering é a disciplina de montar deliberadamente a janela de contexto — decidir o que entra, o que fica de fora, em que ordem, com qual granularidade. Não é um texto estático. É uma construção dinâmica por turno.
Um exemplo direto: você tem um agente de suporte que responde dúvidas técnicas. O prompt está impecável. Mas o agente alucina informações sobre a API do produto. Por quê?
Porque ninguém jogou a documentação atualizada na janela de contexto. O modelo está respondendo baseado no que aprendeu no treinamento — que pode estar desatualizado, incompleto, ou simplesmente errado pro seu produto específico.
Isso não se resolve com prompt. Se resolve com Context Engineering:
- RAG (Retrieval-Augmented Generation): recupera os trechos relevantes da documentação e injeta antes da pergunta
- Compressão de histórico: em conversas longas, resume as interações antigas em vez de mandar tudo sempre
- Progressive disclosure: manda metadados primeiro (nomes de arquivo, headers) e só expande o conteúdo completo quando necessário
- Higiene de saída de ferramentas: quando o agente chama uma API e ela retorna 50KB de JSON, você não manda tudo na janela — você filtra, trunca, extrai o que importa
O CEO da Shopify, Tobi Lütke, descreveu bem: context engineering é "a arte de fornecer todo o contexto para que a tarefa seja plausivelmente solucionável pelo LLM". Não basta dizer o que fazer — o modelo precisa ter os fatos necessários pra fazer certo.
Quando investir em context:
- O modelo dá respostas genéricas quando deveria ser específico
- Alucinações diminuem quando você cola a documentação manualmente no chat
- Em conversas longas, a qualidade cai conforme o histórico cresce
- O custo de tokens explode com o número de usuários
Quando parar de mexer no contexto: Quando o modelo vê os dados certos mas o agente ainda age errado — comete ação duas vezes, ignora um step de aprovação, ou estoura o orçamento de chamadas. Aí o problema é o harness.
Janela de contexto bem montada:
[System Prompt] ← o que o modelo é e o que não deve fazer
[Documentação relevante] ← recuperada via RAG, não estática
[Histórico comprimido] ← resumo das últimas N interações, não o log completo
[Estado atual do sistema] ← o que mudou desde a última ação
[Tool outputs filtrados] ← só o que importa da resposta das ferramentas
[Instrução do turno] ← o que o usuário pediu agora
Harness Engineering: o que envolve o modelo
Essa é a camada que quase ninguém fala — e que faz toda a diferença quando o agente começa a agir no mundo.
Harness é toda a infraestrutura que envolve o modelo. Não é o que você pede (prompt), não é o que o modelo vê (contexto). É o loop completo que converte a saída probabilística do modelo em software que se comporta de forma previsível:
- Orquestração do ciclo (planejar → chamar ferramenta → observar → repetir)
- Timeouts e retries quando a ferramenta falha
- Sandboxing para limitar o que o agente pode tocar
- Gates de aprovação antes de ações irreversíveis
- RBAC: o modelo só pode chamar as ferramentas que aquele usuário tem permissão
- Idempotência: se a mesma ação rodar duas vezes, o resultado é o mesmo
- Circuit breaker: agente gastou $X em tokens? Para. Chamou 30 vezes o mesmo endpoint? Para.
- Audit trail: log de tudo que o agente fez, com quais inputs, com quais resultados
Se você tem um agente de coding (tipo Claude Code, Cursor, ou um próprio) que propõe editar arquivos — quem aplica o patch, roda os testes, verifica que não quebrou nada, e para se falhar? Não é o modelo. É o harness.
Se o agente pode mandar email, criar tarefa no Jira, ou dar merge num PR — quem decide que aquela ação precisa de aprovação humana antes de executar? Não é o prompt. É o harness.
O hype de IA ainda vende Prompt Engineering como a habilidade principal. A dor de produção mora em Context e Harness. É exatamente aqui que demos em produção acontecem, onde o custo explode, onde a confiança do usuário vai embora.
Quando investir em harness:
- O agente pode agir no mundo (não só responder — ele executa, modifica, envia)
- Você precisa de auditoria ("quem autorizou isso?")
- O custo escala com os usuários de forma inesperada
- O agente funciona no demo mas não sobrevive às condições reais
- Ações se repetem, ou ficam em loop sem critério de parada
Sintoma clássico de problema de harness: tudo funciona no playground. Em produção, com usuário real, em carga, com falha intermitente de API — o agente fica preso num loop, ou executa a mesma ação duas vezes, ou não para quando deveria.
Como diagnosticar em qual camada está o seu problema
Isso aqui salvou muito tempo pra mim. Antes de sair ajustando qualquer coisa, pergunta:
O modelo está respondendo algo errado ou no formato errado?
→ Problema de Prompt. Revise as instruções, adicione exemplos, seja mais específico.
O modelo está respondendo certo pro que ele viu, mas o que ele viu estava errado ou incompleto?
→ Problema de Context. Melhore a recuperação, filtre melhor os outputs das ferramentas, comprima o histórico.
O modelo está respondendo certo e vendo as informações certas, mas o agente como sistema ainda falha?
→ Problema de Harness. Falta gate de aprovação, falta idempotência, falta circuit breaker, falta log.
Uma tabela rápida:
| Sintoma | Camada |
|---|---|
| Resposta no formato errado | Prompt |
| Resposta ignora restrição explícita | Prompt |
| Alucina fato que estava na documentação | Context |
| Custo de tokens explode com usuários | Context |
| Qualidade cai em conversa longa | Context |
| Agente age duas vezes na mesma coisa | Harness |
| Demo funciona, produção não | Harness |
| Sem registro de quem fez o quê | Harness |
| Agente não para quando deveria | Harness |
A maturidade do agente
Isso segue uma progressão natural conforme o agente fica mais capaz:
Est�ágio 1 — Copiloto/Q&A: Responde, sugere, não age. Prompt bem feito + contexto mínimo (talvez um pouco de RAG). O harness é basicamente rate limit e logging.
Estágio 2 — Assistente com ferramentas: Chama APIs, lê banco, gera artefatos. Context Engineering vira obrigatório — output de ferramenta precisa ser curado. Harness define a superfície de ferramenta e o tratamento de erro.
Estágio 3 — Agente operacional: Age de forma autônoma, executa fluxos completos, escala para múltiplos usuários, integra com sistemas externos. Aqui o Harness domina. Aprovações, política compartilhada, idempotência, audit trail, ações unificadas entre canais.
A maioria dos times está tentando construir Estágio 3 com só Prompt Engineering de Estágio 1. Daí a frustração.
O que eu aprendi apanhando
Fui no caminho errado várias vezes nessa ordem:
Primeiro erro: ficar ajustando prompt quando o agente alucinava porque não tinha a informação. Passei horas tentando fazer o modelo "não inventar" via instrução. A solução era jogar o documento certo na janela.
Segundo erro: empilhar contexto sem critério. Achar que mandar mais informação sempre ajuda. Não ajuda. Janela grande com lixo é pior que janela pequena com o essencial. O modelo se perde no meio.
Terceiro erro (o pior): deixar o agente agir sem harness porque "tava funcionando nos testes". Aí em produção ele executou uma ação duas vezes porque a API retornou timeout na primeira e ele interpretou como falha. Sem idempotência no harness, sem gate de verificação antes de executar de novo — problema garantido.
Antes de construir um agente que age no mundo, responde essa lista:
- O que acontece se a ferramenta falha? (retry? fallback? para?)
- O que acontece se a ação roda duas vezes? (idempotente? duplica dado?)
- Existe ação irreversível aqui? (se sim, precisa de gate de aprovação)
- Como eu rastreio o que o agente fez? (se não tem log, tem problema)
Conclusão
A distinção não é só semântica. É diagnóstico.
Quando você entende que são três camadas separadas, você para de gastar energia no lugar errado. Não polindo prompt quando o problema é contexto. Não enchendo a janela de tokens quando o problema é que o agente não tem gate de aprovação.
Prompt Engineering resolve como o modelo entende o que você quer.
Context Engineering resolve se o modelo tem as informações certas pra agir.
Harness Engineering resolve se o sistema ao redor do modelo é confiável o suficiente pra ir pra produção.
Agente bom em produção precisa das três. O que muda é a proporção — e saber quando cada uma está te limitando.